DM818 Assignment 1: Optimize Matrix Multiplication
Due Date: XXX , 2009 at 11:59PM
Your task is to optimize matrix multiplication code to run fast on a single processor core of
NERSC Franklin cluster (please read the access instructions). Semantics of the matrix multiplication is:
for i = 1 to n
for j = 1 to n
for k = 1 to n
C[i,j] = C[i,j] + A[i,k] * B[k,j]
end
end
end
where A, B and C are n-by-n matrices. You need to write a dgemm.c
that implements this semantics and exposes it through the following C interface:
void square_dgemm( int n, double *A, double *B, double *C ).
The matrices are stored in column-major order, i.e. entry Cij is stored at C[i+j*M].
The correctness of implementation is verified using an element-wise error bound that holds for the naive matrix multiply:
|square_dgemm(n,A,B,0) - A*B| < eps * n * |A| * |B|.
This bound also holds for any other algorithm that does the same floating point operations as the naive algorithm but in different order.
However, this may exclude using some other algorithms such as Strassen's. In the formula,
eps = 2–52 = 2.2 * 10–16 is the machine epsilon.
We provide two simple implementations for you to start with:
a naive three-loop implementation similar to shown above
and a more cache-efficient blocked implementation.
The necessary files are in matmul.tar. Included are the following:
|
- dgemm-naive.cpp
- A naive implementation of matrix multiply using three loops,
- dgemm-blocked.cpp
- A simple blocked implementation of matrix multiply,
- dgemm-blas.cpp
- A wrapper for vendor's optimized implementation of matrix multiply,
- benchmark.cpp
- The driver program that measures the runtime and verifies the correctness by comparing with ACML,
- Makefile
- A simple makefile to build the executables,
- job-blas, job-blocked, job-naive
- Scripts to run the executables on Franklin compute nodes. For example, type "qsub job-blas" to benchmark the BLAS version.
|
This code uses ACML library, so you may need to type "module load acml" before compiling the code on Franklin to set up the paths.
See instructions in the Makefile on compiling the code with different compilers
available on Franklin.
A detailed help on using the programming environment can be found
on the NERSC pages.
The target processor is Quad Core AMD Opteron. Its cores have separate 128-bit wide pipelines for addition and multiplication clocked at 2.3GHz.
This yields 2 double precision (i.e. 64-bit) flops per pipeline * 2 pipelines * 2.3 GHz = 9.2 Gflop/s.
The following graph shows the performance of the supplied naive and blocked
implementations (if compiled using PGI compiler with -fastsse option)
as a fraction of this peak:
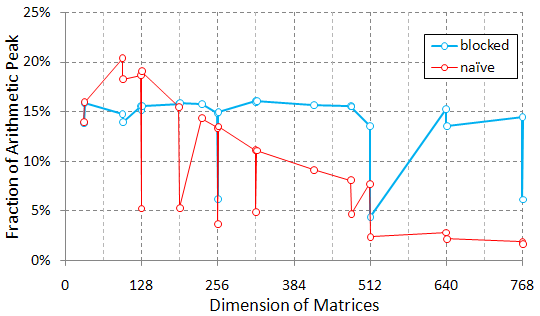
Your goal is to get a higher performance and understand how you did that. Ideally,
you would match or surpass the performance of the BLAS implementation (please check how fast it is), but this is
not required.
The assignment should be done in pairs that are assigned.
Mail me (Vasily) your optimized dgemm.c
(or dgemm.cpp),
Makefile (for compiler options) and a write-up. The write-up should contain
- the names of the people in your group,
- the optimizations used or attempted,
- the results of those optimizations,
- the reason for any odd behavior (e.g., dips) in performance, and
- how the same kernel performs on a different hardware platform.
For the last requirement, you may run your optimized implementation on another NERSC cluster, such as
Bassi (POWER 5 processors) or
DaVinci (Itanium 2 processors),
on your laptop, etc.
Your grade will mostly depend on two factors:
- performance sustained by your codes on Franklin,
- explanations of the performance features you observed.
Useful References
Technical Publications:
- Goto, K., and van de Geijn, R. A. 2008. Anatomy of High-Performance Matrix Multiplication, ACM Transactions on Mathematical Software 34, 3, Article 12.
- Chellappa, S., Franchetti, F., and Püschel, M. 2008. How To Write Fast Numerical Code: A Small Introduction, Lecture Notes in Computer Science 5235, 196–259.
- Bilmes, et al. The PHiPAC (Portable High Performance ANSI C) Page for BLAS3 Compatible Fast Matrix Matrix Multiply.
- Lam, M. S., Rothberg, E. E, and Wolf, M. E. 1991. The Cache Performance and Optimization of Blocked Algorithms, ASPLOS'91, 63–74.
Technical Documentation:
You are also welcome to learn from the source code of state-of-art BLAS implementations
such as GotoBLAS
and ATLAS.
However, you should not reuse those codes in your submission.
[ Back to CS267 Resource Page ]