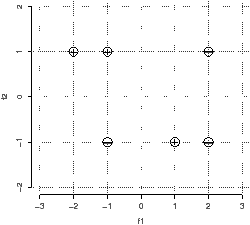
Decision Tree
- Construct a decision tree using the recursive bi-partitioning algorithm based on information gain described in class. (Discretize the continue scale considering for f1 only the values {−1.5,0,1.5} and for f2 only 0.) Represent graphically the tree constructed and draw the decision boundaries in the Figure 1.
- Explain how you chose the top-level attribute in the tree.
Table 1 might be useful.
- Apply χ2 pruning.
- Use the tree to predict the outcome for the new point (1,1).
Nearest Neighbor
- Draw the decision boundaries for 1-Nearest Neighbors on the Figure 1. Make it accurate enough so that it is possible to tell whether the integer-valued coordinate points in the diagram are on the boundary or, if not, which region they are in.
- What class does 1-NN predict for the new point: (1, 1) Explain why.
- What class does 3-NN predict for the new point: (1, 0) Explain why.
- In general, how would you select between two alternative values of k for use in k-nearest neighbors?
Perceptron
- Imagine to apply the perceptron learning algorithm to the points in Figure 1. Describe qualitatively what the result would be.
- (a) In Boolean logic, the majority function is a function from n inputs to one output. The value of the operation is false when n/2 or more arguments are false, and true otherwise. Draw a network that represent the majority function for 4 input nodes.
- (b) Draw a network that represent the “exactly two out of three” function for three inputs.
- (c) Draw a network to simulate the XOR operator in Boolean logic. XOR (exclusive-or) is a logical operator that results in the output being true if one of the inputs, but not both, is true. If both inputs are true the output is false.
nnet from package nnet, rpart from package
rpart, knn from package class, the glm
function (check example in ?predict.glm). Look at the examples
of these methods by ?function. nnet uses one hidden
layer. To implement the single layer perceptron you may try to use the
following lines for stochastic gradient descent with the needed
changes:| sigma <- function(w,point) { x <- c(point,1) sign(w %*% x) } w.0 <- c(runif(1),runif(1),runif(1)) w.t <- w.0 for (j in 1:1000) { i <-sample(1:50,1) # or (j-1)%%50 + 1 diff <- y[i,3] - sigma(w.t, c(x[i,1],x[i,2])) w.t <- w.t+0.2*diff * c(x[i,1],x[i,2],1) } |
Test also the batch version of gradient descent.
More data to analyse are available at UCI Machine Learning Repository.