Suppose you have two containers, initially empty. One has a capacity of exactly 3 liters; the other has a capacity of 5 liters. You can pour water from one container to another, empty a container, or fill a container at any time. Your problem is to place exactly 4 liters of water in the 5-liter container. Describe how this problem could be framed as a search problem defining the related components. Solve the problem within this framework and report the search performed.
- [a)]Suppose that on Monday night, Albert’s office is equally likely to be light or dark. What is the probability that his office will be lit all the other four nights of the week (Tuesday through Friday)?
- Suppose that you observe that his office is lit on both Monday and Friday nights. Compute the expected number of nights, from that Monday through Friday, that his office is lit.
Now suppose that Albert has been working for five years (i.e., assume that the Markov chain is in steady state).
- Is his light more likely to be on or off at the end of a given workday?
Consider a Naive Bayes problem with three features, x1, x2, x3. Imagine that we have seen a total of 16 training examples, 8 positive (with y = 1) and 8 negative (with y = 0). In Table 1 you find some of the counts.
What are the values estimated from the data for the following parameters:
- Pr(x1 = 1|y = 0)=θ10,
- Pr(x2 = 1|y = 1)=θ21,
- Pr(x3 = 0|y = 0)=1−θ30?
(You need to show the full derivation, answers by intuition without analytical justification do not count.)
Figure 1 shows a graphical model with conditional probabilities tables about whether or not you will panic at an exam based on whether or not the course was boring (“B”), which was the key factor you used to decide whether or not to attend lectures (“A”) and revise doing the exercises after each lecture (“R”).
[ place/.style=ellipse,draw=black!50,fill=black!20,thick, inner sep=0pt,minimum size=1cm, pre/.style=<-,shorten <=1pt,>=angle 60,semithick, post/.style=->,shorten >=1pt,>=stealth’,semithick, transition/.style=rectangle,draw=black!100,fill=black!20,thick, inner sep=0pt,minimum size=3mm] [place] (b) at (1,4) B; [place] (r) at (0,2) R edge [pre] (b); [place] (a) at (2,2) A edge [pre] (b); [place] (p) at (1,0) P edge [pre] (r) edge [pre] (a); [left,minimum height=2cm, minimum width=2cm] (b2) at (b.west); [left,minimum height=2cm, minimum width=2cm] (r2) at (r.west)
; [right,minimum height=2cm, minimum width=2cm] (a2) at (a.east)
; [left,minimum height=2cm, minimum width=2cm] (p2) at (p.west)
;
Figure 1: The graphical model of exercise on Bayesian Network Inference. Lower-case letter indicate the outcome that the upper-case letter can take.
You should use the model to make exact inference and answer the following queries:
- =3exwhat is the probability that you will panic or not before the exam given that you attended the lectures and revised after each lecture?
- what is the probability that you will panic or not before the exam?
- Your teacher saw you panicking at the exam and he wants to work out from the model the reason for that. Was it because you did not come to the lecture or because you did not revise?
Describe how stochastic inference methods like Prior-Sample, Rejection-Sampling, Likelihood-weighting and Markov Chain Monte Carlo could be used to answer the queries above.
[ place/.style=ellipse,draw=black!50,fill=white,thick, inner sep=0pt,minimum size=0.5cm, placeb/.style=ellipse,draw=black!50,fill=black!20,thick, inner sep=0pt,minimum size=0.5cm, pre/.style=<-,shorten <=1pt,>=angle 60,semithick, post/.style=->,shorten >=1pt,>=stealth’,semithick, transition/.style=rectangle,draw=black!100,fill=black!20,thick, inner sep=0pt,minimum size=3mm] [place] (1) at (0,2) 1; [placeb] (2) at (0.5,1) 2; [place] (7) at (2.5,2) 7; [place] (8) at (4,2) 8; [place] (6) at (1,2) 6 edge [pre] (1) edge [pre] (2); [place] (10) at (1,0) 10 edge [pre] (2); [place] (4) at (1.5,1) 4 edge [pre] (6) edge [pre] (2) edge [pre] (7); [place] (3) at (2,0) 3 edge [pre] (10); [placeb] (9) at (2.5,1) 9 edge [pre] (7) edge [pre] (8) edge [pre] (3); [place] (5) at (3,0) 5 edge [pre] (9);
- Write down the standard factorization for the given graph.
- For what pairs (i, j) does the statement Xi is independent of Xj hold? (Don’t assume any conditioning in this part.)
- Suppose that we condition on {X2, X9}, shown shaded in the graph. What is the largest set A for which the statement X1 is conditionally independent of XA given {X2, X9} holds?
- What is the largest set B for which X8 is conditionally independent of XB given {X2, X9} holds?
- Suppose that I wanted to draw a sample from the marginal distribution p(x5) = Pr[X5 = x5]. (Don’t assume that X2 and X9 are observed.) Describe an efficient algorithm to do so without actually computing the marginal.
Express the output of a neural network with one single hidden layer as a function of the input parameters when the activation function at the units is a linear function. Assume the same linear function at each unit. Would it be possible to simplify the network to a one layer perceptron?
Suppose we collected the daily measurement of the thickness of the ozone layer above Palmerston North in New Zealand between 1996 and 2004. Ozone thickness is measured in Dobson units, which are 0.01 mm thickness at 0 degree Celsius and 1 atmosphere pressure. The reduction in stratosferic ozone is partly responsible for global warming and the increased incidence of skin cancer. The thickness of the ozone varies naturally over the year as you can see from Figure 3.
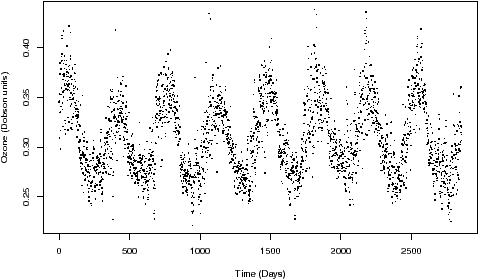
Design an application of multi-layer perceptron to predict the ozone levels into the future and report your design choices specifying inputs and outputs for the problem and consequently the input and output nodes for the network.
Consider the binary classification problem of spam email in which a binary label Y ∈ {0, 1} is to be predicted from a feature vector X = (X1, X2, …, Xn), where Xi=1 if the word i is present in the email and 0 otherwise. Consider a naive Bayes model, in which the components Xi are assumed mutually conditionally independent given the class label Y.
- [a] Draw a directed graphical model corresponding to the naive Bayes model.
- Find a mathematical expression for the posterior class probability p(Y = 1 | x), in terms of the prior class probability p(Y = 1) and the class-conditional densities p(xi | y).
- Make now explicit the hyperparameters of the Bernoulli distributions for Y and Xi. Call them, µ and θi, respectively. Assume a beta distribution for the prior of these hyperparameters and show how to learn the hyperparameters from a set of training data d=(yj,x→j)j=1m using a Bayesian approach. Compare this solution with the one developed in class via maximum likelihood.
- Calculate P (B, C) and P (B).
- Are A and C independent given B? (Remember to report the justification of your answer.)