DM841 (E21) - Heuristics and Constraint Programming for Discrete Optimization
Vehicle Routing Case
At the DIMACS Implementation Challenge on Vehicle Routing you find the description of eight variants of the vehicle routing problem. You can choose one and focus on that one. The higher the number of the problem chosen the more challenging the solution is but also the more rewarding could be the grade.
Choose some test instances with the following criterion: there should be no ceil or floor effect when used as benchmark suite for your algorithms.
If you choose to solve the Capacitated Vehicle Routing Problem (CVRP), in the following sections you find a description of the problem, pointers to test instances and a starting package in Python to work with those instances and draw solutions. If you have chosen other variants of VRP you can still see if you can reuse the code provided for your purposes but you do not have to. You could jump directly to the section “Your Tasks”.
Capacitated Vehicle Routing
In vehicle routing problems we are given a set of transportation requests and a fleet of vehicles and we seek to determine a set of vehicle routes to perform all (or some) transportation requests with the given vehicle fleet at minimum cost; in particular, we decide which vehicle handles which requests in which sequence so that all vehicle routes can be feasibly executed.
The capacitated vehicle routing problem (CVRP) is the most studied version of vehicle routing problems.
In the CVRP, the transportation requests consist of the distribution of goods from a single depot, denoted as point $0$, to a given set of $n$ other points, typically referred to as customers, $N={1,2,\ldots,n}$. The amount that has to be delivered to customer $i\in N$ is the customer’s demand, which is given by a scalar $q_i\geq 0$, e.g., the weight of the goods to deliver. The fleet $K={1,2,\ldots,|K|}$ is assumed to be homogeneous, meaning that $|K|$ vehicles are available at the depot, all have the same capacity $Q>0$, and are operating at identical costs. A vehicle that services a customer subset $S\subseteq N$ starts at the depot, moves once to each of the customers in $S$, and finally returns to the depot. A vehicle moving from $i$ to $j$ incurs the travel cost $c_{ij}$.
The given information can be structured using an undirected graph. Let $V={0}\cup N={0,1,\ldots,n}$ be the set of vertices (or nodes). It is convenient to define $q_0:=0$ for the depot. In the symmetric case, when the cost for moving between $i$ and $j$ does not depend on the direction, i.e., either from $i$ to $j$ or from $j$ to $i$, the underlying graph $G=(V,E)$ is complete and undirected with edge set $E={e=(i,j)=(j,i) : i,j\in V,i\neq j}$ and edge costs $c_{ij}$ for ${i,j} \in E$. Overall, a CVRP instance is uniquely defined by a complete weighted graph $G=(V,E,c_{ij},q_i)$ together with the size $|K|$ of the of the vehicle fleet $K$ and the vehicle capacity $Q$.
A route (or tour) is a sequence $r=(i_0,i_1,i_2,\ldots,i_s,i_{s+1})$ with $i_0=i_{s+1}=0$, in which the set $S={i_1,\ldots,i_s}\subseteq N$ of customers is visited. The route $r$ has cost $c(r)=\sum_{p=0}^sc_{i_p,i_{p+1}}$. It is feasible if the capacity constraint $q(S):=\sum_{i\in S}q_i\leq Q$ holds and no customer is visited more than once, i.e., $i_j\neq i_k$ for all $1\leq j\leq k\leq s$. In this case, one says that $S\subseteq N$ is a feasible cluster. A solution to a CVRP consists of $K$ feasible routes, one for each vehicle $k\in K$. The routes $r_1,r_2,\ldots,r_{|K|}$ and the corresponding clusters $S_1,S_2,\ldots,S_{|K|}$ provide a feasible solution to the CVRP if all routes are feasible and the clusters form a partition of $N$. Hence, the CVRP consists of two interdependent tasks:
(i) the partitioning of the customer set $N$ into feasible clusters $S_1,\ldots,S_{|K|}$;
(ii) the routing of each vehicle $k\in K$ through ${0}\cup S_k$.
Starting Package
Associated to this document there is a GIT repository at: https://github.com/DM865/CVRP.
The repository is made of a directory data/ containing the instances,
a directory src/ containing some initial Python 3 code to read the
instances, output a solution and produce a graphical view of solutions.
The code provides also a framework within which to organize your
implementation. The directory tex contains the sources of this
document and can be therefore ignored.
Instances
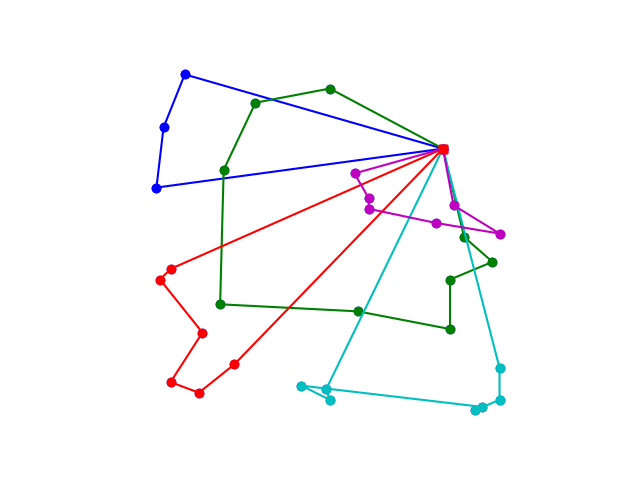
In the directory data/ you find the instance A-n32-k05.xml that is a
small toy instance with 32 nodes. This instance and a heuristic solution
is represented in the figure.
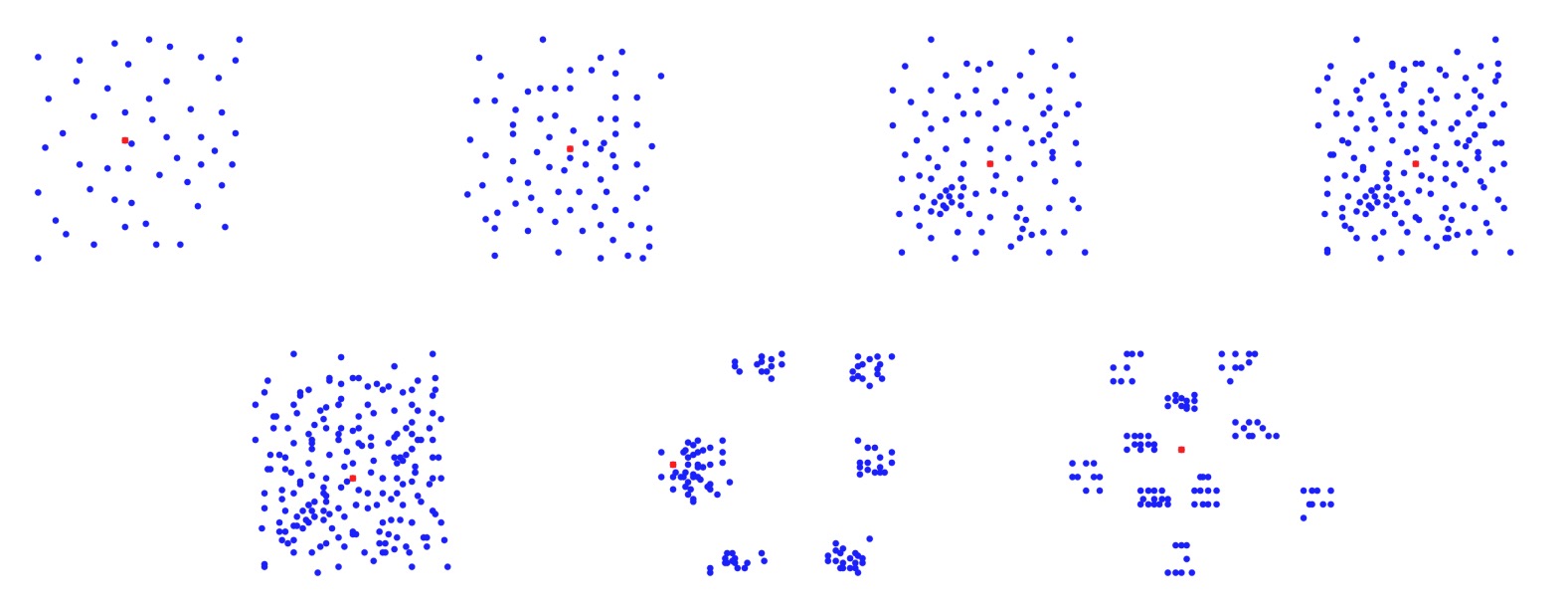
In the directory data/CMT you find the set CMT[^1] of middle size
instances with number of nodes ranging between 51 and 200, and in the
directory data/Golden you find the set Golden[^2] of large size
instances with number of nodes ranging between 241 and 484. The
displacement of the nodes in these instances is depicted in the
following two figures.

The best known solutions for these instances are reported in the table. A star indicates that the solution has been proven optimal.
| instance | nodes | best known |
|---|---|---|
| CMT01 | 51 | 524.61* |
| CMT02 | 76 | 835.26* |
| CMT03 | 101 | 826.14* |
| CMT04 | 151 | 1028.42* |
| CMT05 | 200 | 1291.29* |
| CMT11 | 121 | 1042.11* |
| CMT12 | 101 | 819.56* |
| instance | nodes | best known |
|---|---|---|
| Golden_01 | 241 | 5623.47 |
| Golden_02 | 321 | 8404.61 |
| Golden_03 | 401 | 11036.22 |
| Golden_04 | 481 | 13592.88 |
| Golden_05 | 201 | 6460.98 |
| Golden_06 | 281 | 8404.26 |
| Golden_07 | 361 | 10102.68 |
| Golden_08 | 441 | 11635.34 |
| Golden_09 | 256 | 579.71 |
| Golden_10 | 324 | 736.26 |
| Golden_11 | 400 | 912.84 |
| Golden_12 | 484 | 1102.69 |
| Golden_13 | 253 | 857.19 |
| Golden_14 | 321 | 1080.55 |
| Golden_15 | 397 | 1337.92 |
| Golden_16 | 481 | 1612.50 |
| Golden_17 | 241 | 707.76 |
| Golden_18 | 301 | 995.13 |
| Golden_19 | 361 | 1365.60 |
| Golden_20 | 421 | 1818.32 |
Source Code
The Python code in the directory src/ contains the following files:
-
data.pythat implements the classDatato maintain the data associated with the input instance. It contains an instance reader for the XML format. Objects of this class contain the following data that will be relevant to you:capacitygiving the capacity of the vehicle andnodesthat is a tuple container of the nodes of the given network. Each element from the tuplenodesis a dictionary with the following keys and values:id, the original identifier of the node from the input file,pt, the coordinates of the node in complex numbers notation as we saw for the TSP,tp, the type of customer: 0 if a depot and 1 if a customer,rq, the quantity demanded by the node (if it is a depot this value is 0). Nodes in the tuplenodesare organized in such a way that the depot is the first element followed by all others. Each node can be accessed in constant time through the index in the tuple. Hence, internally the depot has always index zero.The class
Datacontains also methods for printing the instance, reporting statistics, calculating distances and plotting. -
solution.pythat implements the classSolutionto store data relative to a candidate solution. For now it assumes to store the solution in a list of lists, calledroutes. However, this is up to changes according to your needs. It then assumes that you finish implementing the methodsvalid_solutionandcostthat determine the feasibility and the quality of the candidate solution.The class
Solutioncontains also methods for writing the solution file and for plotting the solution. These methods assume that solutions are represented as lists of lists, where every inner list representing a route starts with the depot and ends with the depot. Note that the solution writer outputs the original identifier of the nodes and not the one used to represent them internally. -
solverCH.pythat implements the classConstructionHeuristics. Currently only a canonical construction is implemented that routes costumers in the order they are stored. The implementation might be helpful to see how to use the data from an object of classData. -
solverLS.pythat implements the classLocalSearch. -
main.pythat implements the main program defining the objects and calling the methods defined in the other files. It provides a starting example that can be modified at your best convenience. It also defines the parameters to be specified when the program is run.
The program is executed as specified below:
$ python3 main.py -h
usage: main.py [-h] [-o OUTPUT_FILE] -t TIME_LIMIT instance_file
positional arguments:
instance_file The path to the file of the instance to solve
optional arguments:
-h, --help show this help message and exit
-o OUTPUT_FILE The file where to save the solution and, in case, plots
-t TIME_LIMIT The time limit
marco@nat-102098:~/IMADA/DM865/CVRP/src$
for example:
python3 main.py -t 30 -o A-n32-k05 ../data/A-n32-k05.xml
Included in the directory there is also a Makefile that can be used to
automatize tasks. For example, the call above can be also achieved with:
make A-n32-k05
In addition, in the Makefile there is an example on how to use the code
profiler: cProfile.
It is possible to modify all these files and to add new ones.
Your Tasks
-
Design and implement one or more construction heuristics.
-
Design and implement one or more iterative improvement algorithms. They must terminate in a local optimum.
-
Design and implement metaheuristic algorithms. They can use as components the elements from points 1. and 2. used either as black boxes or modified according to the metheuristic principles.
-
Undertake an experimental analysis where you compare the algorithms from points 1. and 2. and configure the algorithms from point 3. to perform best on average on instances of the largest type. Overall never exceed one minute of running time for a single run of an algorithm.
-
Describe the work done in a report of at most 10 pages. The report must at least contain a description of the best algorithm designed and the experimental analysis conducted. The level of detail must be such that it makes it possible for the reader to reproduce your work.
-
Include in the report a table with the results obtained on the given instances by the best algorithm.
-
Submit your work making sure that the code provided will execute the best algorithm with a time limit of one minute when run from command line as follows:
python3 src/main.py -s 1 -o OUTPUT_FILE -t 60 INSTANCE_FILEand reports in
OUTPUT_FILEthe best solution found in the format explained below. The parameters-sand-tare for the random see and the time limit in seconds, respectively.
Remarks
Remark 1 Make sure and give evidence that the results obtained by the algorithms in the point 3. above are better then those obtained in point 1. and 2.
Remark 2 The metaheuristics designed in point 3. can be any among those encountered in the lectures. More specifically, you can choose one or more algorithm templates among those from the groups treated in class:
- stochastic local search and local search based metaheuristics
- construction based metaheuristics
- population based metaheuristics
A few, well thought algorithms are better than many naive ones. However, it is expected that you compare a few alternatives.
Remark 3 You should be able to indicate in your report the name of the metahuristic(s) implemented. If your algorithm differ in some elements from the standard templates of the metaheuristics seen in class you must state that in the report and if it is an original attempt you should try to indicate which approach seen in class gets closer to it.
Remark 4 This is a list of factors that will be taken into account in the evaluation (possibly in order of importance):
- correctness of results claimed after running the submitted program
- quality of the final results;
- level of detail of the study;
- complexity and originality of the approaches chosen;
- presence of the analysis of the computational costs involved in the main operations of the local search.
- organization of experiments that guarantees reproducibility of conclusions;
- clarity of the report;
- effective use of graphics in the presentation of experimental results.
- correctness in the classification of the algorithms, that is, using the right names for the metaheuristics described
Output Format
i) it must execute the heuristic that you chose as the best one when called as follows:
python3 main.py -t 30 -o [an_instance] ../data/[an_instance].xml
The program must solve the specified instance and halt before the
specified time limit.
ii) At termination the program must write the solution in the format
described below in a file whose name is the one given for the
parameter -o plus the extension .sol. The starting code provided
has a function write_to_file to do this but probably you will need
to modify it if you change the solution representation. The function
is called from the main file. The solution written in the file must
be valid, that is, feasible.
Right after the submission the program will be tested and if it does not satisfy the requiremets above you will receive an email and the submission will be invalid.
In addition, the submission system will execute your program and compare it against your peers on a set of unspecified instances. Therefore, you should submit your best algorithm early and eventually revise your submission. Before submitting, test your implementation on the IMADA machines. If you are using additional python modules not present in setting of the Computer Lab machines, write to Marco.
Solution file
The solution file must list the routes one per line. Each route is a comma separated list of nodes to be visited in the given order. The node identifier must be the original one from the input file. Routes must start with the depot and finish with the depot.
The following listing provides an example of solution file for a valid solution to the instance CMT02:
76,1,2,3,4,5,6,7,76
76,8,9,10,11,12,13,76
76,14,15,16,17,18,19,20,76
76,21,22,23,24,25,26,27,76
76,28,29,30,31,32,76
76,33,34,35,36,37,38,39,76
76,40,41,42,43,44,45,76
76,46,47,48,49,50,51,52,76
76,53,54,55,56,57,58,59,76
76,60,61,62,63,64,65,66,76
76,67,68,69,70,71,72,73,74,75,76
Solutions files have extension .sol.