Weekly Notes for Week 18
-
Please note: Intentionally a superset of the exercises to be covered in the tutorial section is listed. The intention is to make you aware of what you should be able to solve with enough time and the slides/book/video lecture available, and to give you material for the preparation of the exam (some of the questions indeed introduce new content, but that is usually not the case). Several of the exercises have now attributes, if they are, e.g., deemed to be very important.
-
Due to the university lockdown we will still use Zoom for online teaching and this week also for the tutorials. The exercises are Friday, 10am.
-
In the lecture in week 18 we finish the few parts left of Chapter 13 (File-System Interface), and will then continue with Chapter 14 (File-System Implementation) and Chapter 15 (File-System Internals). We will cover the missing Chapter 12 after this.
Tutorial Session Week 18
See also the Weekly Notes from Week 17, as there are still important exercises from Chapter 10 to be discussed. In addition prepare the following exercises from the second part of Chapter 10 and from Chapter 11:
Chapter 10
- Assume that a program has just referenced an address in virtual
memory. Describe a scenario in which each of the following can
occur. (If no such scenario can occur, explain why.)
- TLB miss with no page fault
- TLB miss with page fault
- TLB hit with no page fault
- TLB hit with page fault
- Important Consider a system that uses pure demand paging.
- When a process first starts execution, how would you characterize the page-fault rate?
- Once the working set for a process is loaded into memory, how would you characterize the page-fault rate?
- Assume that a process changes its locality and the size of the new working set is too large to be stored in available free memory. Identify some options system designers could choose from to handle this situation.
-
repetition The following is a page table for a system with 12-bit virtual and physical addresses and 256-byte pages. Free page frames are to be allocated in the order 9, F, D. A dash for a page frame indicates that the page is not in memory.
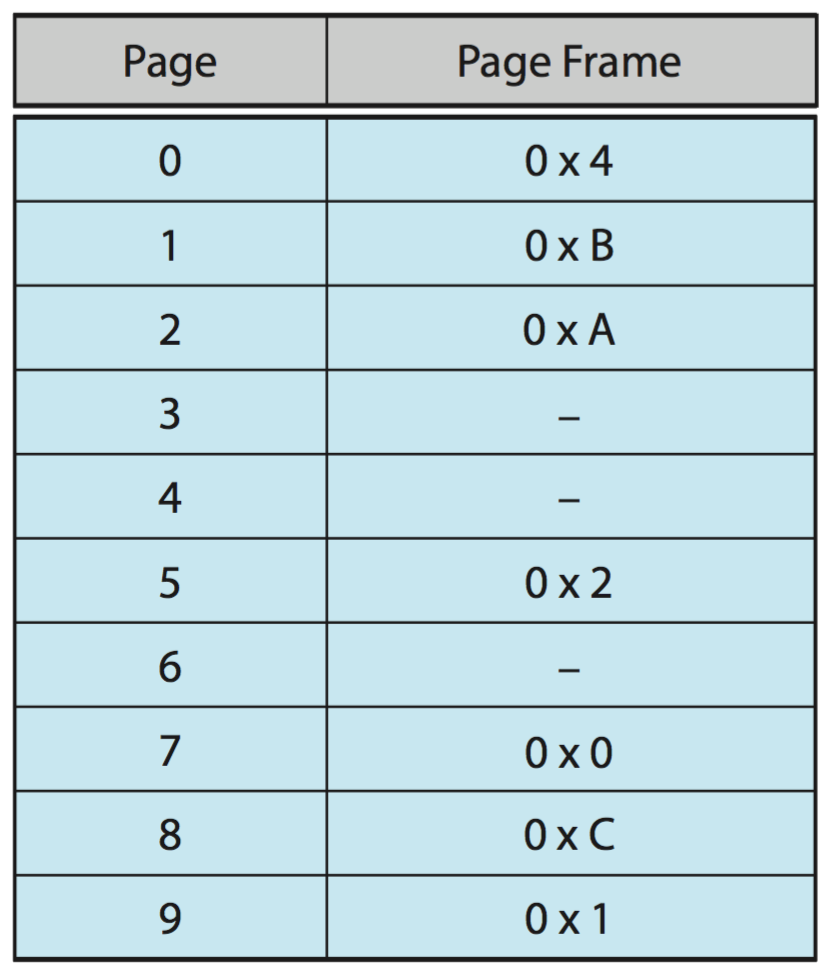
Convert the following virtual addresses to their equivalent physical addresses in hexadecimal. All numbers are given in hexadecimal. In the case of a page fault, you must use one of the free frames to update the page table and resolve the logical address to its corresponding physical address.
-
Consider the page table for a system with 16-bit virtual and physical addresses and 4,096-byte pages.
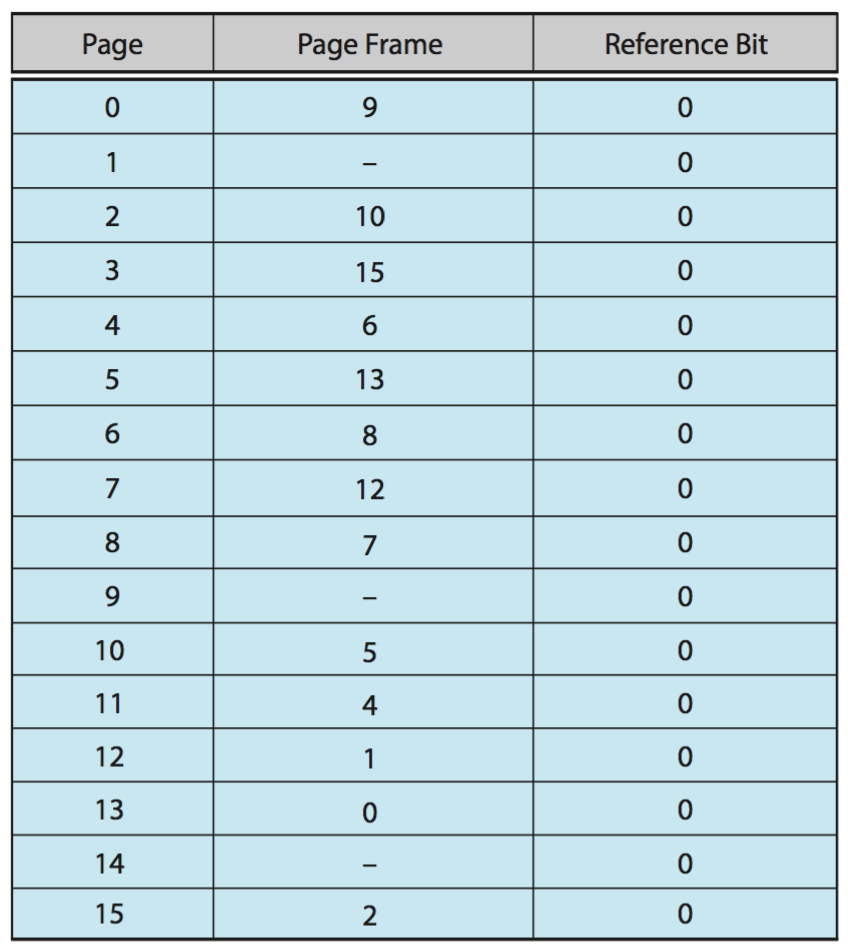
The reference bit for a page is set to 1 when the page has been referenced. Periodically, a thread zeroes out all values of the reference bit. A dash for a page frame indicates that the page is not in memory. The page-replacement algorithm is localized LRU, and all numbers are provided in decimal.
- Convert the following virtual addresses (in hexadecimal) to the
equivalent physical addresses. You may provide answers in either
hexadecimal or decimal. Also set the reference bit for the
appropriate entry in the page table.
0x621C0xF0A30xBC1A0x5BAA0x0BA1
-
Using the above addresses as a guide, provide an example of a logical address (in hexadecimal) that results in a page fault.
- From what set of page frames will the LRU page-replacement algorithm choose in resolving a page fault?
- Convert the following virtual addresses (in hexadecimal) to the
equivalent physical addresses. You may provide answers in either
hexadecimal or decimal. Also set the reference bit for the
appropriate entry in the page table.
- (repetition) Apply the (1) FIFO, (2) LRU, and (3) optimal (OPT) replacement algorithms for the following paGe-reference strings:
2, 6, 9, 2, 4, 2, 1, 7, 3, 0, 5, 2, 1, 2, 9, 5, 7, 3, 8, 50, 6, 3, 0, 2, 6, 3, 5, 2, 4, 1, 3, 0, 6, 1, 4, 2, 3, 5, 73, 1, 4, 2, 5, 4, 1, 3, 5, 2, 0, 1, 1, 0, 2, 3, 4, 5, 0, 14, 2, 1, 7, 9, 8, 3, 5, 2, 6, 8, 1, 0, 7, 2, 4, 1, 3, 5, 80, 1, 2, 3, 4, 4, 3, 2, 1, 0, 0, 1, 2, 3, 4, 4, 3, 2, 1, 0
-
Discuss situations in which the least frequently used (LFU) page-replacement algorithm generates fewer page faults than the least recently used (LRU) page-replacement algorithm. Also discuss under what circumstances the opposite holds.
- The KHIE (pronounced “k-hi”) operating system uses a FIFO
replacement algorithm for resident pages and a free-frame pool of
recently used pages. Assume that the free-frame pool is managed using the LRU
replacement policy. Answer the following questions:
- If a page fault occurs and the page does not exist in the free-frame pool, how is free space generated for the newly requested page?
- If a page fault occurs and the page exists in the free-frame pool, how are the resident page set and the free-frame pool managed to make space for the requested page?
- To what does the system degenerate if the number of resident pages is set to one?
- To what does the system degenerate if the number of pages in the free-frame pool is zero?
-
Explain why compressed memory is used in operating systems for mobile devices.
-
Suppose that your replacement policy (in a paged system) is to examine each page regularly and to discard that page if it has not been used since the last examination. What would you gain and what would you lose by using this policy rather than LRU or second-chance replacement?
-
(important) Is it possible for a process to have two working sets, one representing data and another representing code? Explain.
- (important) In a 1,024-KB segment, memory is allocated using the buddy system.
Which allocations are made (you could draw a tree illustrating the
allocations) after the following memory requests are allocated:
- Request 5-KB
- Request 135 KB.
- Request 14 KB.
- Request 3 KB.
- Request 12 KB.
Next, modify the tree/allocations for the following releases of memory. Perform coalescing whenever possible:
- Release 3 KB.
- Release 5 KB.
- Release 14 KB.
- Release 12 KB.
- (interesting) The slab-allocation algorithm uses a separate cache for each different object type. Assuming there is one cache per object type, explain why this scheme doesn’t scale well with multiple CPUs. What could be done to address this scalability issue?
Chapter 11
-
(important) Explain why SSTF scheduling tends to favor middle cylinders over the innermost and outermost cylinders.
-
(important) Why is it important to balance file-system I/O among the disks and controllers on a system in a multitasking environment?
-
What are the tradeoffs involved in rereading code pages from the file system versus using swap space to store them?
-
Is there any way to implement truly stable storage? Explain your answer.
- (rather easy, but will take long) It is sometimes said that tape is a sequential-access medium, whereas
a hard disk is a random-access medium. In fact, the suitability of a
storage device for random access depends on the transfer size. The
term streaming transfer rate denotes the rate for a data transfer that is
underway, excluding the effect of access latency. In contrast, the effective transfer rate is the ratio of total bytes to total seconds, including
overhead time such as access latency.
Suppose we have a computer with the following characteristics: the
level-2 cache has an access latency of 8 nanoseconds and a streaming
transfer rate of 800 megabytes per second, the main memory has an
access latency of 60 nanoseconds and a streaming transfer rate of 80
megabytes per second, the hard disk has an access latency of 15 milliseconds and a streaming transfer rate of 5 megabytes per second, and
a tape drive has an access latency of 60 seconds and a streaming transfer
rate of 2 megabytes per second.
- Random access causes the effective transfer rate of a device to decrease, because no data are transferred during the access time. For the disk described, what is the effective transfer rate if an average access is followed by a streaming transfer of (1) 512 bytes, (2) 8 kilobytes, (3) 1 megabyte, and (4) 16 megabytes?
- The utilization of a device is the ratio of effective transfer rate to streaming transfer rate. Calculate the utilization of the disk drive for each of the four transfer sizes given in part 1.
- Suppose that a utilization of 25 percent (or higher) is considered acceptable. Using the performance figures given, compute the smallest transfer size for a disk that gives acceptable utilization.
- Complete the following sentence: A disk is a randomaccess device for transfers larger than bytes and is a sequential-access device for smaller transfers.
- Compute the minimum transfer sizes that give acceptable utilization for cache, memory, and tape.
- When is a tape a random-access device, and when is it a sequential-access device?
-
Could a RAID level 1 organization achieve better performance for read requests than a RAID level 0 organization (with nonredundant striping of data)? If so, how?
-
(important) Give three reasons to use HDDs as secondary storage.
-
(important) Give three reasons to use NVM devices as secondary storage.
- None of the disk-scheduling disciplines, except FCFS, is truly fair (starvation may occur).
- Explain why this assertion is true.
- Describe a way to modify algorithms such as SCAN to ensure fairness.
- Explain why fairness is an important goal in a multi-user systems.
- Give three or more examples of circumstances in which it is important that the operating system be unfair in serving I/O requests.
- (easy) Suppose that a disk drive has 5,000 cylinders, numbered 0 to 4,999. The
drive is currently serving a request at cylinder 2,150, and the previous
request was at cylinder 1,805. The queue of pending requests, in FIFO
order, is:
2,069; 1,212; 2,296; 2,800; 544; 1,618; 356; 1,523; 4,965; 3,681Starting from the current head position, what is the total distance (in cylinders) that the disk arm moves to satisfy all the pending requests for each of the following disk-scheduling algorithms?- FCFS
- SCAN
- C-SCAN
-
(repetition) Compare and contrast HDDs and NVM devices. What are the best applications for each type?
- (important) Consider a RAID level 5 organization comprising five disks, with the
parity for sets of four blocks on four disks stored on the fifth disk. How
many blocks are accessed in order to perform the following?
- A write of one block of data
- A write of seven continuous blocks of data
-
Assume that you have a mixed configuration comprising disks organized as RAID level 1 and RAID level 5 disks. Assume that the system has flexibility in deciding which disk organization to use for storing a particular file. Which files should be stored in the RAID level 1 disks and which in the RAID level 5 disks in order to optimize performance?
- (important) The reliability of a storage device is typically described in terms of mean
time between failures (MTBF). Although this quantity is called a “time,”
the MTBF actually is measured in drive-hours per failure.
- If a system contains 1,000 disk drives, each of which has a 750,000hour MTBF, which of the following best describes how often a drive failure will occur in that disk farm: once per thousand years, once per century, once per decade, once per year, once per month, once per week, once per day, once per hour, once per minute, or once per second?
- (far-going camparison) Mortality statistics indicate that, on the average, a U.S. resident has about 1 chance in 1,000 of dying between the ages of 20 and 21. Deduce the MTBF hours for 20-year-olds. Convert this figure from hours to years. What does this MTBF tell you about the expected lifetime of a 20-year-old?
- The manufacturer guarantees a 1-million-hour MTBF for a certain model of disk drive. What can you conclude about the number of years for which one of these drives is under warranty?
- Discuss the reasons why the operating system might require accurate information on how blocks are stored on a HDD disk. How could the operating system improve file-system performance with this knowledge?