DM818 Mandatory Assignment 3:
You need to work on one of the two options that are described below. Note that the deadline (19.12., 10am) is absolutely strict due to formal reasons.
Option 1: DNS Algorithm (Deckel, Nassimi, Sahni), preliminary (small changes to be expected)
Overview
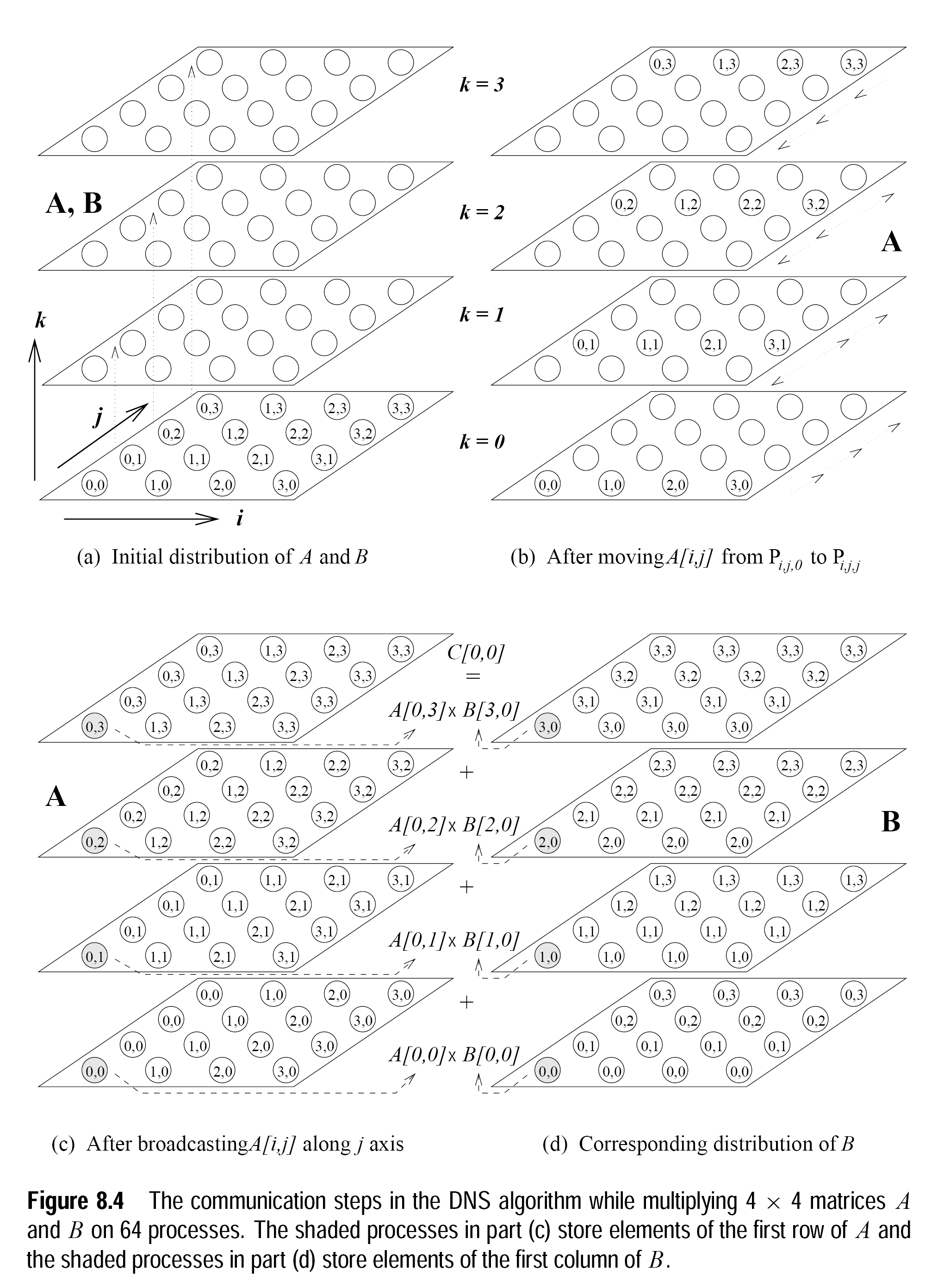
The purpose of this assignment is to parallelize matrix-matrix multiplication with the DNS algorithm (see Chapter 8 of the course book).
Implement the DNS algorithm for dense matrix multiplication using MPI on the Franlin cluster. Use a virtual topology as a mechanism for naming the processes in the communicator (see for example here). The implementation has only to be functional for a cubic number p of processors and you can assume that the matrices of size n×n have a certain size, namely it holds n ≥ p1/3. Furthermore you can assume that the input matrices are squared. Note that your implementation has to handle the case that the matrix dimension n is not divisible by p1/3. For the multiplication of the submatrices you are required to use Cray's LibSci (cmp. Mandatory Assignment 1).
Let the overall runtime of the matrix-matrix multiplication be defined as Pend-Pstart. Pstart refers to the time that corresponds to the situation (a) on Figure 8.4 page 350 of the course book (see below, i.e. the time after the submatrices have been scattered from one to n2 processors), Pend refers to the time when the All-to-One reduction step along the k axis of DNS is finished (i.e. the time before the submatrices are gathered to one processor which is identical to the time directly after the All-to-One reduction step along the k axis has finished in all n2 processors).
Source Code
You may (but you don't have to) start with the implementation template supplied below.
|
Although you do not need to use this template, your executable
should in any case be named dnsmat, and it should use exactly two parameters,
namely the number of processors and the matrix dimension (for example
the command ./dnsmat 8 240 will execute the DNS
matrix-matrix multiplication algorithm on two matrices of size
240×240 with 8 cores).
You are welcome to use any NERSC cluster in this assignment.
Resources
- The main source of information is Chapter 8 of the course book. Virtual topologies are (for example) explained here.
Report / Submission
The assignment can be done alone, or in groups of two or three people (preferably groups of two). The submission of the source code has to be supplemented by a write-up (max. 10 pages), one write-up for the whole group. The write-up should contain in any case:
- The names of the people in your group.
- A statement of who contributed with what.
- A description of the design choices that you tried and how they affected the performance.
- A description of how you used virtual topologies.
- In your report, all runtimes and measures that depend on runtimes, should be
based on average runtimes based on 10 test runs (compare
main.c). - A table and a figure similar to Figure 5.8 and Table 5.1 on page 211 of the course book with reasonably chosen values for the number of processors p and matrix dimension n. As matrix-matrix multiplication with a small number of processors can take very long for large matrices, you should omit certain combination of p and n. (You may restrict computation time via the #PBS -l walltime=XX:XX:XX command in the batch file.) However you have to include (p,n) ∈ {(125,25),(125,10000),(1000,100),(1000,10000)} and a column for p=1. For determining the speedup and the efficiency you shall not compare your measured parallel runtimes to actual runtimes using p=1, but you shall assume a 19.2 Gflop/s peak performance per processor and infer the sequential runtime for p=1 based on that assumption. (Therefore the column "p=1" will have efficiency values <1.0 that are identical to the fraction of peak performance based on Cray's LibSci runtime measurements from the first mandatory assignment.)
- A table with the same columns and
rows as the table given above, where the entries should give the
percentage of the overall runtime that was spend for computation
(use
MPI_Wtimefor measuring computation times between communication periods on one node only). - A table with the same columns and rows as the table given above,
where the entries should give the overall runtime in seconds
(use
MPI_Wtimefor measuring computation times between communication periods on one node only). - A discussion of your results and a discussion that compares your results to the isoefficiency function O(p (log p)3).
- A description of how you solved the problem when the matrix dimension n is not divisible by p1/3.
- Your matrices for multiplication should have randomly chosen elements between 0 and 1. The matrices have to be defined on one node and then the submatrices have to be distributed according to the DNS algorithm to the other nodes. Furthermore the data should be gathered in the end to one node (this is also necessary for the correctness check, see next paragraph). Note however how the overall runtime of the matrix-matrix multiplication is defined!
- Your source code has to include a method that checks for a randomly chosen element of the resulting matrix, that the outcome of the parallel matrix multiplication is identical to the result that is computed in O(n) time on one node (that is the difference is smaller that a reasonably chosen small value). The correctness check should not influence the overall runtime measurements. Your executable has to perform the correctness check on at least one element.
For submitting the report and the sources proceed as follows: Create the following directory structure one of IMADAs pool machines (of course you have to copy the data from the NERSC filesystem to the IMADA system before doing that, and you have to modify the directory names below if you use different systems than Edison for your implementation).
mandatory3/ mandatory3/report/ mandatory3/mpi-edison/sources/ mandatory3/mpi-edison/results/
Put your report, sources, and results in the corresponding
directory. The source directory should include all files that are
necessary to produce an executable code on the corresponding NERSC
resources. The sources directory and
the results directory should also contain
a README file that describes details. It basically has to
be possible to copy the complete sources to the file system of the
system of your choice, and to produce executable files via a
simple make command. The report directory,
the sources directory, and the results
directory should not contain more than 10MB of data each.
After putting all the data to the correct location, change to the directory mandatory3 and type aflever DM818 your@email.dk.
Additionally, you shall hand in a printout of your report and of your source code (10 pages limit applies only to the report, not to the source code).
The strict deadline for submission (electronically and printouts) is December, 19th, 10:00pm.
Option 2: Free Project
Overview
The purpose of this assignment is apply methods and techniques you learned to a project of your own choice. You choose an algorithm to be parallelized and to be analyzed yourself. The following requirements have to be fulfilled:
- You are required to submit an implementation that can be executed on Edison.
- You have to use the message-passing paradigm for your implementation.
- It should be possible to use a large number of processors to solve the problem of your choice with your implementation (at least hundreds).
- Communication overhead, scalability, and efficiency have to be analyzed empirically. If an isoefficiency analysis is easily possible, then it has to be done. You should consider simplifications that may make an analytical isoefficiency analysis possible.
- You should try to choose a problem that is not too similar to a problem for which the isoefficiency analysis is aleady discussed in the course book. Very easy problems for which a scalability analysis is trivial are not acceptable.
Project suggestions will be given in week 48/49, however you are very welcome to not follow the project suggestions. Note that the course book is also a source for finding projects proposals (especially the exercise part of Chapters 8-13).
This option for the last mandatory assignment is solved in two phases:
Option 2, Phase 1
In phase 1 of this assignment you have to submit a short problem specification. This document should have a length of approx. 0.5 - 1 page. Within this document you should give the following information:
- The names of the people in your group.
- What problem are you going to solve?
- How are you going to investigate scalability? (Are you planning to do an isoefficiency analysis? Are you planning to use other scalability measures? Are you planning to investigate the communication overhead analytically?)
- Literature that you are going to use and that you already know of.
- Contact e-mail address(es) that we should use for sending you our response.
For submitting the required problem specification, proceed as follows: Use this template and give me the printout of your specification.
The strict deadline for submission (electronically and the print-out) is Wednesday, December, 4th, 15:15am. You will either get the information that no changes are required, or we might request for a re-submission.
Option 2, Phase 2
In phase 2 you follow the plan we agreed upon (justified changes during phase 2 are of course possible, however you have to inform me in the case of significant changes). As usual, you have to hand in a written report, the source code of your implementation, and the results.
Report / Submission
The assignment can be done in groups of two or three people (preferably groups of two or three, in exceptional cases you can also work alone). The submission of the source code has to be supplemented by a write-up (max. 15 pages), one write-up for the whole group. The write-up should contain in any case:
- The names of the people in your group.
- A statement of who contributed with what.
- An introduction and a specification of the problem.
- A discussion of related work that you used or that you found related enough to be mentioned (note that you are requested to search for related literature).
- A description of the design choices that you tried and how they affected the performance.
- A discussion and a description of the tests that you performed and what the outcome was.
- An analytical and/or and empirical analysis of scalability and/or isoefficiency.
- A conclusion.
- A list of references.
For submitting the report and the sources proceed as follows: Create the following directory structure on one of IMADAs pool machines:
mandatory3-phase2/ mandatory3-phase2/report/ mandatory3-phase2/sources/ mandatory3-phase2/results/
Put your report, sources, and results in the corresponding
directory. The sources directory should include all files that are
necessary to produce an executable code on Edison. The sources directory and
the results directory should also contain
a README file that describes details. It basically has to
be possible to copy the complete sources to the file system of the
system of your choice, and to produce executable files via a
simple make command. The report directory,
the sources directory, and the results
directory should not contain more than 10MB of data each.
After putting all the data to the correct location, change to the directory mandatory3, and zip the directory. Please submit your files via blackaord.
Additionally, you shall hand in a printout of your report and of your source code (15 pages limit applies only to the report, not to the source code).
The strict deadline for submission (electronically and printouts) is December, 19th, 10:00am.
Frequently Asked Questions (FAQ)
- Are we allowed to work in groups?
Yes, but you should clearly state who contributed with what in the report. The mandatory assignments are part of your final exam, i.e., you have to fully understand all parts of what you have done.