Wireshark HTTP
Introduction
Having gotten our feet wet with the Wireshark packet sniffer in the introductory lab, we’re now ready to use Wireshark to investigate protocols in operation.
In this lab, we’ll explore several aspects of the HTTP protocol: the basic GET/response interaction, HTTP message formats, retrieving large HTML files, retrieving HTML files with embedded objects, and HTTP authentication and security. Before beginning these labs, you might want to review Section 2.2 of the text
The Basic HTTP GET/response interaction
Let’s begin our exploration of HTTP by downloading a very simple HTML file - one that is very short, and contains no embedded objects. Do the following:
-
Start up your web browser.
-
Start up the Wireshark packet sniffer, as described in the Introductory lab (but don’t yet begin packet capture). Enter “http” (just the letters, not the quotation marks) in the display-filter-specification window, so that only captured HTTP messages will be displayed later in the packet-listing window. (We’re only interested in the HTTP protocol here, and don’t want to see the clutter of all captured packets).
-
Wait a bit more than one minute (we’ll see why shortly), and then begin Wireshark packet capture.
-
Enter the following to your browser http://wireshark.grydeske.net/file1.html Your browser should display the very simple, one-line HTML file.
-
Stop Wireshark packet capture.
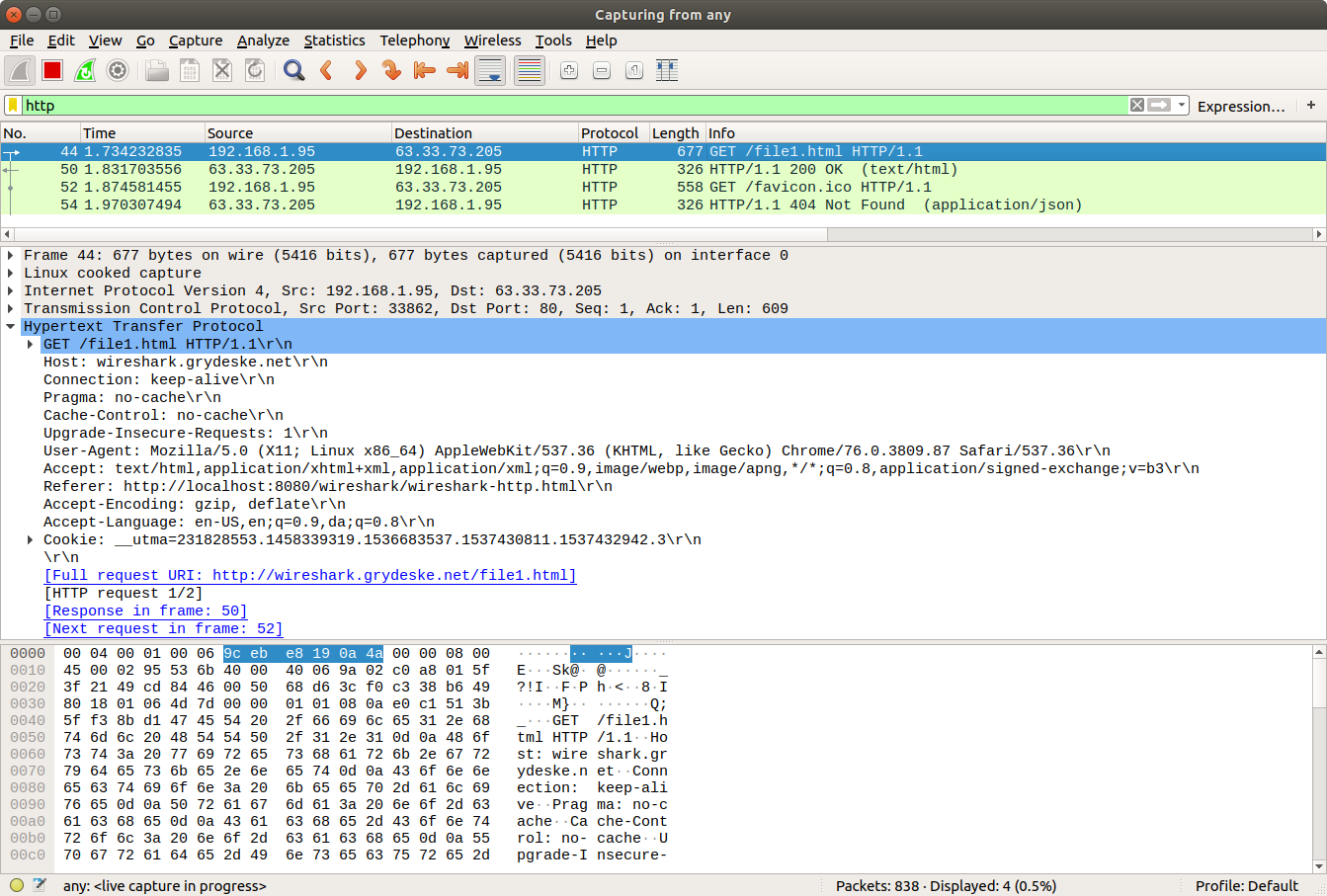
Your Wireshark window should look similar to the window shown below.
Figure 1: Wireshark after HTTP Get request
The example in Figure 1 shows in the packet-listing window that four HTTP messages were captured: the GET message (from your browser to the wireshark.grydeske.net server) and the response message from the server to your browser, and a request for the favicon.ico that is not available - please just ignore this pair.
The packet-contents window shows details of the selected message (in this case the HTTP GET request, which is highlighted in the packet-listing window). Recall that since the HTTP message was carried inside a TCP segment, which was carried inside an IP datagram, which was carried within an Ethernet frame, Wireshark displays the Frame, Ethernet, IP, and TCP packet information as well. We want to minimize the amount of non-HTTP data displayed (we’re interested in HTTP here, and will be investigating these other protocols is later labs), so make sure the boxes at the far left of the Frame, Ethernet, IP and TCP information have a plus sign or a right-pointing triangle (which means there is hidden, undisplayed information), and the HTTP line has a minus sign or a down-pointing triangle (which means that all information about the HTTP message is displayed).
Tasks and Questions
By looking at the information in the HTTP GET and response messages, answer the following questions.
-
Is your browser running HTTP version 1.0 or 1.1? What version of HTTP is the server running?
-
What languages (if any) does your browser indicate that it can accept to the server?
-
What is the IP address of your computer? Of the wireshark.grydeske.net server?
-
What is the status code returned from the server to your browser?
-
How many bytes of content are being returned to your browser?
-
By inspecting the raw data in the packet content window, do you see any headers within the data that are not displayed in the packet-listing window? If so, name one.
Retrieving Long Documents
In the previous example, the document retrieved have been a simple and short HTML file. Let’s next see what happens when we download a long HTML file. Do the following:
-
Start up your web browser.
-
Start up the Wireshark packet sniffer
-
Enter the following URL into your browser http://wireshark.grydeske.net/file3.html Your browser should display the rather lengthy "Bill of Rights".
-
Stop Wireshark packet capture, and enter “http” in the display-filter-specification window, so that only captured HTTP messages will be displayed.
In the packet-listing window, you should see your HTTP GET message, followed by a multiple-packet TCP response to your HTTP GET request. This multiple-packet response deserves a bit of explanation. Recall from Section 2.2 (see Figure 2.9 in the text) that the HTTP response message consists of a status line, followed by header lines, followed by a blank line, followed by the entity body. In the case of our HTTP GET, the entity body in the response is the entire requested HTML file. In our case here, the HTML file is rather long, and at 4500 bytes is too large to fit in one TCP packet. The single HTTP response message is thus broken into several pieces by TCP, with each piece being contained within a separate TCP segment (see Figure 1.24 in the text). In recent versions of Wireshark, Wireshark indicates each TCP segment as a separate packet, and the fact that the single HTTP response was fragmented across multiple TCP packets is indicated by the “TCP segment of a reassembled PDU” in the Info column of the Wireshark display. Earlier versions of Wireshark used the “Continuation” phrase to indicated that the entire content of an HTTP message was broken across multiple TCP segments.. We stress here that there is no “Continuation” message in HTTP!
Tasks and Questions
Answer the following questions:
-
How many HTTP GET request messages did your browser send? Which packet number in the trace contains the GET message for the Bill or Rights?
-
Which packet number in the trace contains the status code and phrase associated with the response to the HTTP GET request?
-
What is the status code and phrase in the response?
-
How many data-containing TCP segments were needed to carry the single HTTP response and the text of the book?
HTML Documents with Embedded Objects
Now that we’ve seen how Wireshark displays the captured packet traffic for large HTML files, we can look at what happens when your browser downloads a file with embedded objects, i.e., a file that includes other objects (in the example below, image files) that are stored on another server(s).
Do the following:
-
Start up your web browser, and make sure your browser’s cache is cleared, as discussed above.
-
Start up the Wireshark packet sniffer
-
Enter the following URL into your browser http://wireshark.grydeske.net/file4.html Your browser should display a short HTML file with two images. These two images are referenced in the base HTML file. That is, the images themselves are not contained in the HTML; instead the URLs for the images are contained in the downloaded HTML file. As discussed in the textbook, your browser will have to retrieve these logos from the indicated web sites.
-
Stop Wireshark packet capture, and enter “http” in the display-filter-specification window, so that only captured HTTP messages will be displayed.
Tasks and Questions
Answer the following questions:
-
How many HTTP GET request messages did your browser send? To which Internet addresses were these GET requests sent?
-
Can you tell whether your browser downloaded the two images serially, or whether they were downloaded in parallel? Explain.
HTTP Authentication (Basic Auth)
Finally, let’s try visiting a web site that is password-protected and examine the sequence of HTTP message exchanged for such a site.
The URL http://wireshark.grydeske.net/file5.html is password protected. The username is "dm557" (without the quotes), and the password is "network" (again, without the quotes). So let’s access this “secure” password-protected site.
Do the following:
-
Start up your web browser.
-
Start up the Wireshark packet sniffer
-
Enter the following URL into your browser http://wireshark.grydeske.net/file5.html
-
Type the requested user name and password into the pop up box.
-
Stop Wireshark packet capture, and enter “http” in the display-filter-specification window, so that only captured HTTP messages will be displayed.
Tasks and Questions
Answer the following questions:
-
What is the server’s response (status code and phrase) in response to the initial HTTP GET message from your browser?
-
When your browser’s sends the HTTP GET message for the second time, what new field is included in the HTTP GET message?
The username (dm557) and password (network) that you entered are encoded in the string of characters (ZG01NTc6bmV0d29yaw==) following the “Authorization: Basic” header in the client’s HTTP GET message. While it may appear that your username and password are encrypted, they are simply encoded in a format known as Base64 format. The username and password are not encrypted! To see this, go to http://www.motobit.com/util/base64-decoder-encoder.asp and enter the base64-encoded string ZG01NTc6bmV0d29yaw== and decode. Voila! You have translated from Base64 encoding to ASCII encoding, and thus should see your username and password!
Since anyone can download a tool like Wireshark and sniff packets (not just their own) passing by their network adaptor, and anyone can translate from Base64 to ASCII (you just did it!), it should be clear to you that simple passwords on WWW sites are not secure unless additional measures are taken.
Fear not! As we will see in Chapter 8, there are ways to make WWW access more secure. However, we’ll clearly need something that goes beyond the basic HTTP authentication framework!